
跟着单细胞测序技艺的迅猛发展和商场的不绝下千里,越来越多的商讨东说念主员都可爱于使用该技艺来推崇一些生物学或医常识题,使通过传统bulk-RNA测序无法惩处的事情得以杀青成为可能,如细胞图谱的画图、珍稀细胞的果决与识别、细胞发育/分化轨迹的构建、肿瘤的缜密化商讨等。与此同期,也产生了海量的单细胞数据,而这些数据频繁开始于不同的实验室,具有不同的构建时辰、不同的操作主说念主员以及不同的试剂批次等等。上述相反常常会对数据的合并形成严重的影响,导致批次效应的出现,进而搅扰对信得过的生物学效应的辩别,因此,若何将不同开始的数据无缺地系在一齐一直是一个复杂的、具有挑战性的问题。在以前的十几年间,罕有十种数据整合顺序接踵被开导出来,它们基于不同的旨趣或应用场景杀青对数据的合并,在保留生物学相反的同期尽可能地去除批次效应。这里黄药师,咱们接收了一些比较常见的用具或顺序,包含ComBat、BBKNN、Seurat CCA、Seurat RPCA、Harmony、LIGER、fastMNN、Conos、Scanorama整个9种,通过应用于归并套数据对其进行比较。
在线影院jjj85
上期《单细胞分析雕塑师--常见整合顺序比较(一)》为巨匠带来了4类常见的整合顺序,本期推送接续为巨匠带来Harmony、fastMNN等更多整合顺序。
Results
05 Harmony
Harmony[3]使用迭代聚类顺序来对王人不同数据集的细胞 (Figure7)。该算法领先将数据连结起来,并使用PCA将数据投影到一个低纬空间中,然后,Harmony使用一个迭代轨范来去除批次效应。每一次迭代包括四个法子:
1)使用一种自界说的k-means软聚类顺序将细胞聚类;
2)为每个聚类盘算推算一个全局质心,为每个特定数据集盘算推算一个质心;
3)使用上步成果盘算推算每一个数据集的矫正因子;
4)终末,依据细胞特定因子——一组经过加权的数据集矫正因子的线性组合——来矫正细胞。
近似法子1~4直到箝制。该顺序复返的是细胞的低纬镶嵌。咱们使用默许参数初始 harmony::RunHarmony ,并收用成果的前30个主要素(此处指复返的Harmony向量)进行细胞聚类过火它分析。
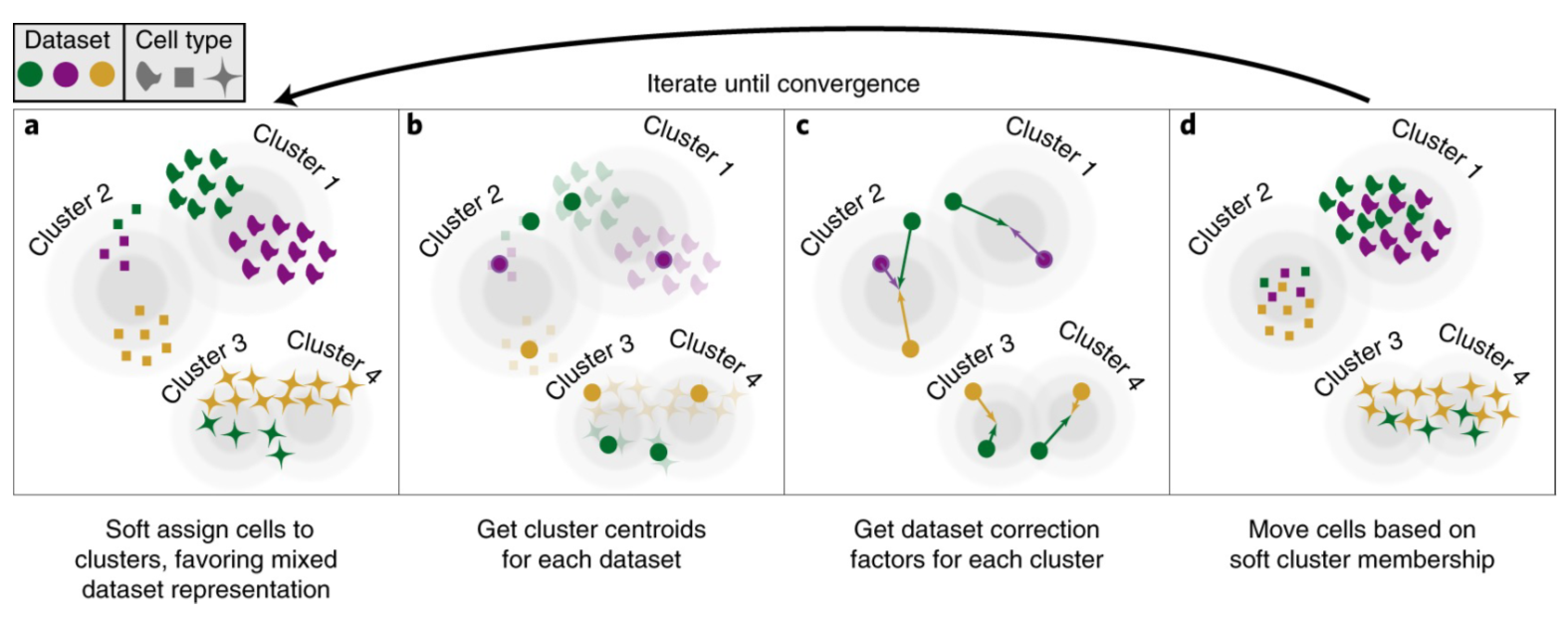
Figure7| Harmony算法时势图。使用PCA将细胞镶嵌低纬空间,Harmony在该降维空间中试验迭代轨范。

Figure8| Harmony 整合分析成果。左边为UMAP降维图形展示,隔离以数据集和细胞类型分组;右图是成果评分。
06 fastMNN
fastMNN是由MNN[4]更始而来,大要愈加速速地杀青多量据的整合。MNN(Mutual Nearest Neighbors) 通过在不同数据集间寻找互隔邻(MNNs)来进行数据的整合(Figure9),该顺序的主要法子为,领先对基因抒发矩阵作念处理,并进行余弦尺度化,然后盘算推算细胞之间的欧氏距离以寻找MNNs,在配对细胞中存在的抒发相反被用于盘算推算矫正向量,终末应用到整个细胞上。比拟于MNN径直哄骗基因抒发来盘算推算距离,fastMNN则是在PCA的基础上来赢得最隔邻。咱们收用了前3000个HVGs用于这次整合分析。
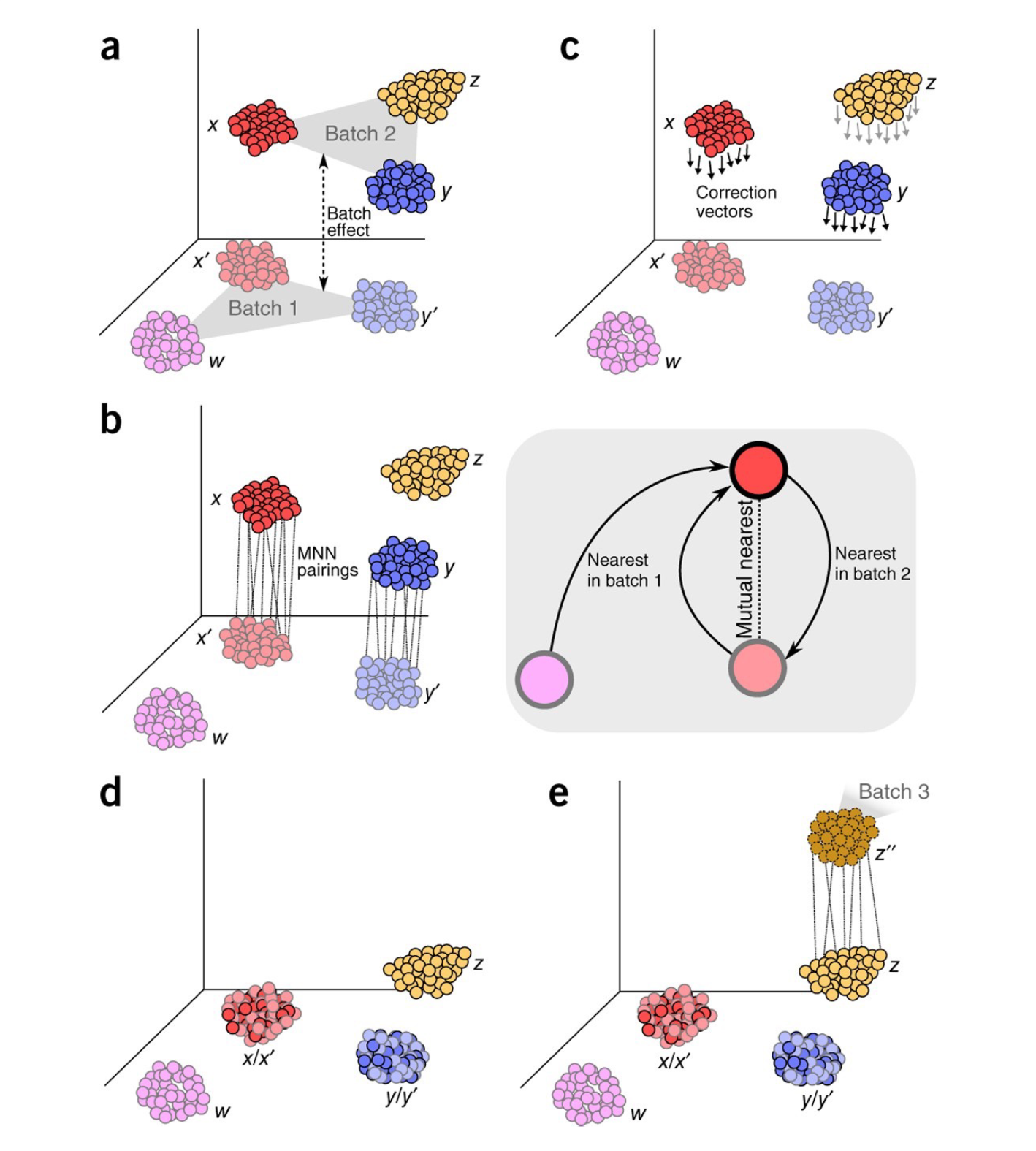
Figure9| MNN算法时势图。该算法通过寻找两个高维数据Batch1和Batch2之间的MNNs(灰色方框)笃定细胞对,Batch1行动Reference,从而盘算推算矫正向量,然后应用到Batch2中何况合并到Batch1中。整合后的数据可行动新的Reference
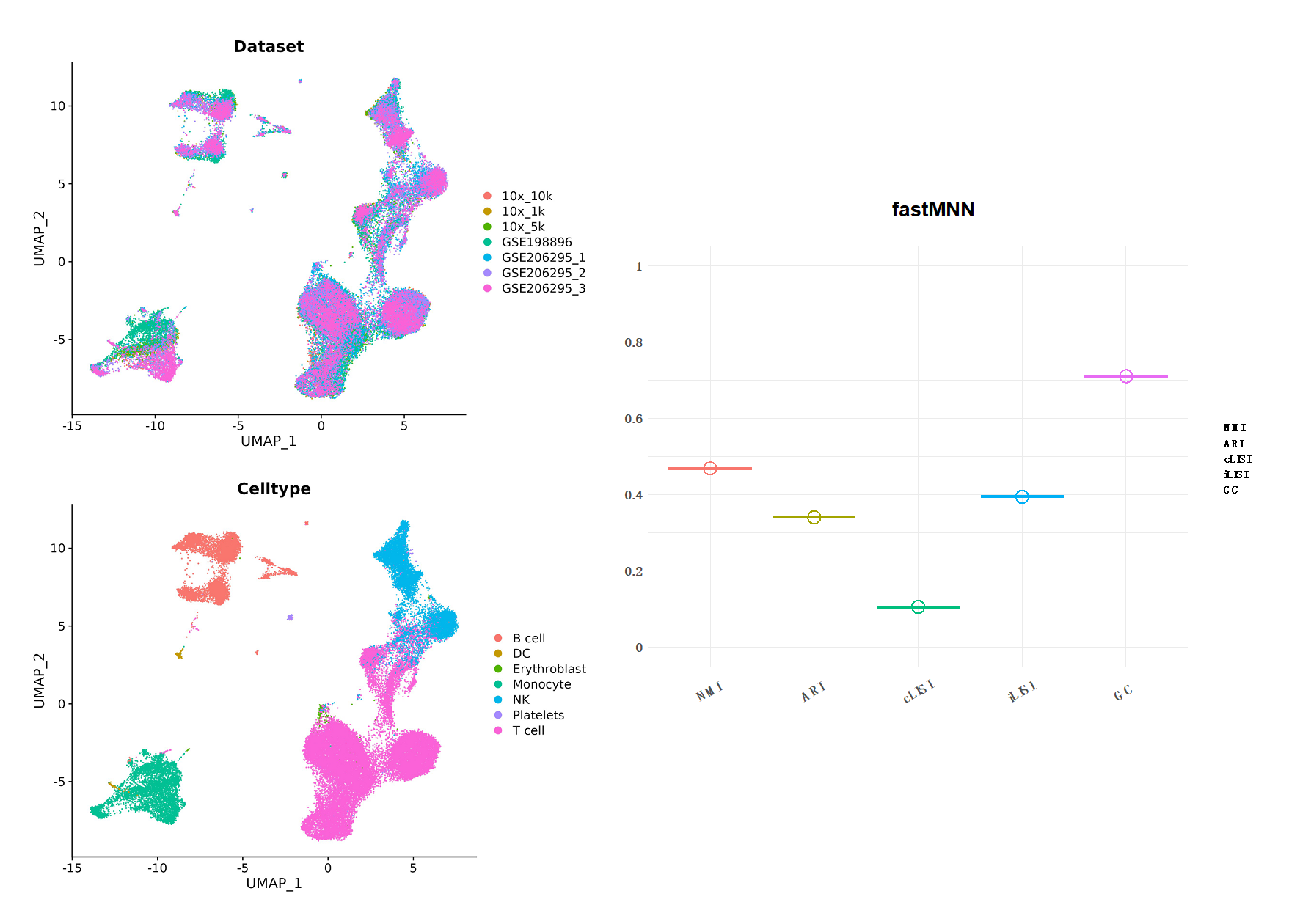
Figure10| fastMNN 整合分析成果。左边为UMAP降维图形展示,隔离以数据集和细胞类型分组;右图是成果评分
07 BBKNN
BBKNN(Batch Balanced K Nearest Neighbours) 是一个爽直、快速、愈加轻量级的数据整合用具[5]。它大要在一个低纬空间中径直盘算推算最隔邻并构建隔邻图,该图形摒除了来自不同批次的数据的影响(Figure11)。另外,该用具主要基于Python话语编写,因此,关于BBKNN,咱们主要基于Scanpy的分析经过,使用 bbknn.bbknn 代替 scanpy.pp.neighbors,并以前30个PCs行动输入用于数据的整合。
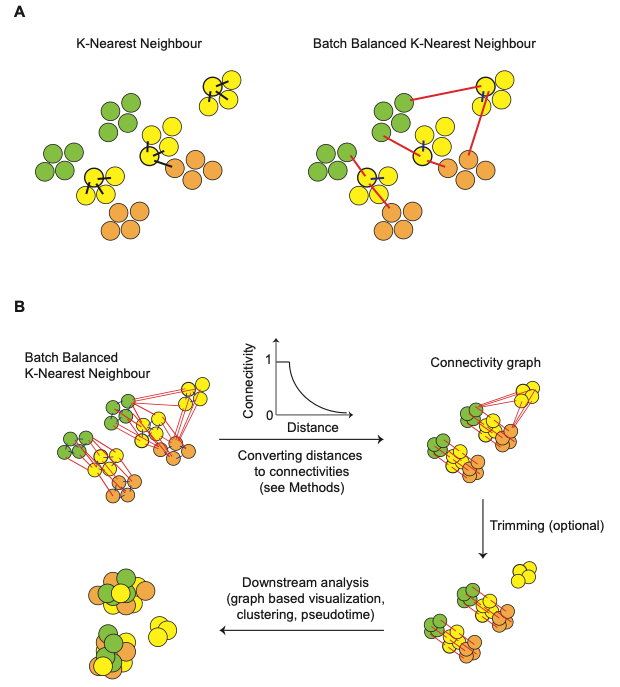
Figure11| BBKNN算法时势图。图A简单展示了一个细胞的kNN及BBKNN的成果,对每一个细胞,BBKNN司帐算其在每个批次中的最隔邻。图B展示了图形的构建过程,将距离更正成指数关系的相连,同期对成果进行修剪,移除不实相连
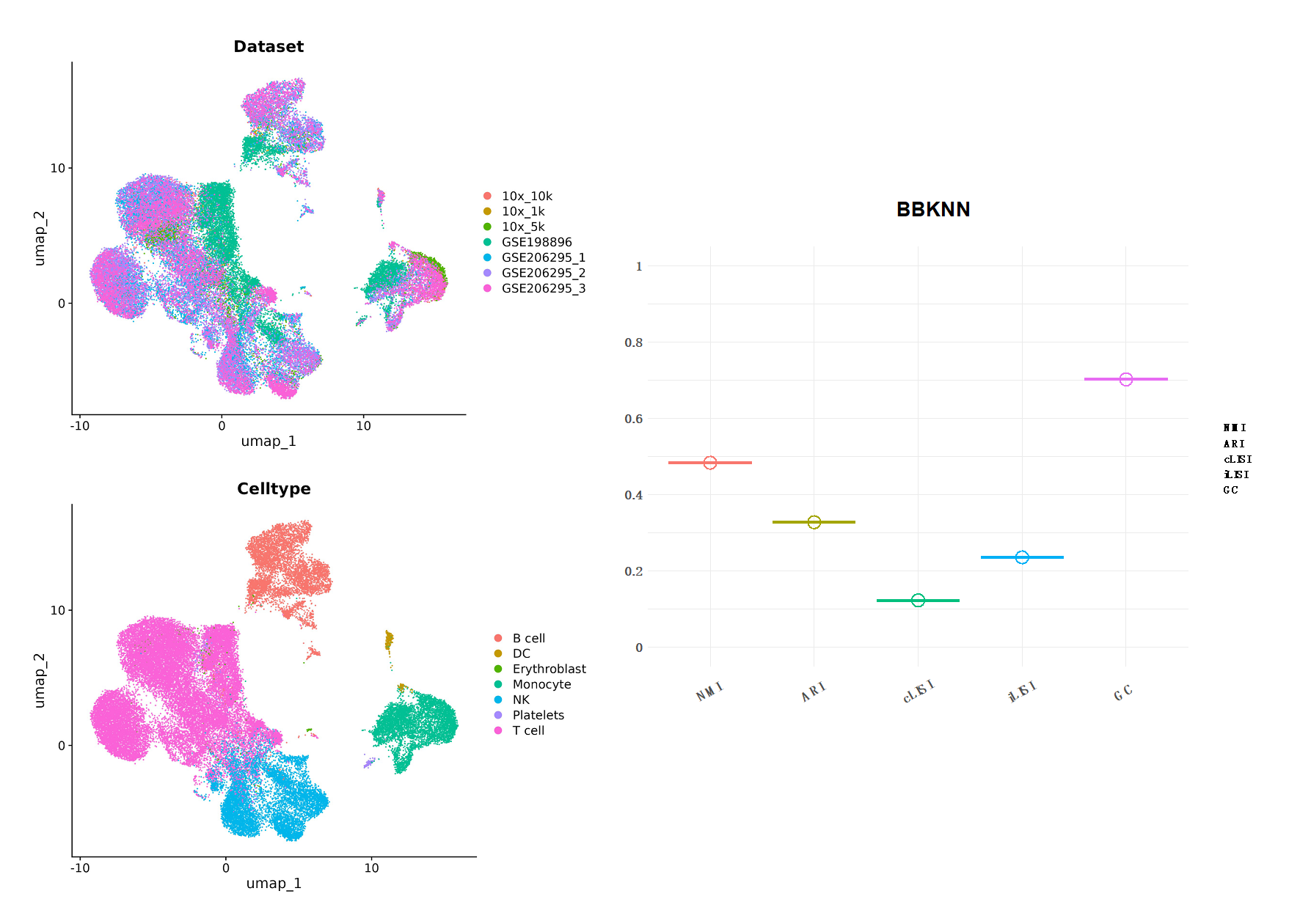
Figure12| BBKNN 整合分析成果。左边为UMAP降维图形展示,隔离以数据集和细胞类型分组;右图是成果评分
08 LIGER
LIGER[6]主淌若基于iNMF(integrative non-Negative Matrix Factorization) 顺序杀青不同数据批次效应的识别(Figure13)。赢得输入数据后,LIGER和会过iNMF将原数据解析,学习得到新的低纬空间,在该空间内,每个细胞都由两组因子界说,一组是数据集特异因子,一组是分享因子,其中每一个因子都表征一种生物信号。通过构建分享因子隔邻图,后者继而被用于识别不同数据集的相同细胞。终末使用最大的数据批次行动参考对因子负载分位数进行尺度化以杀青批次改良。在本次分析中,咱们指定关键参数 "k=20, λ=5" 来初始 rliger::optimizeALS 函数,其中,k代表了解析因子的数目, λ用于调度数据集特异因子对成果的影响。
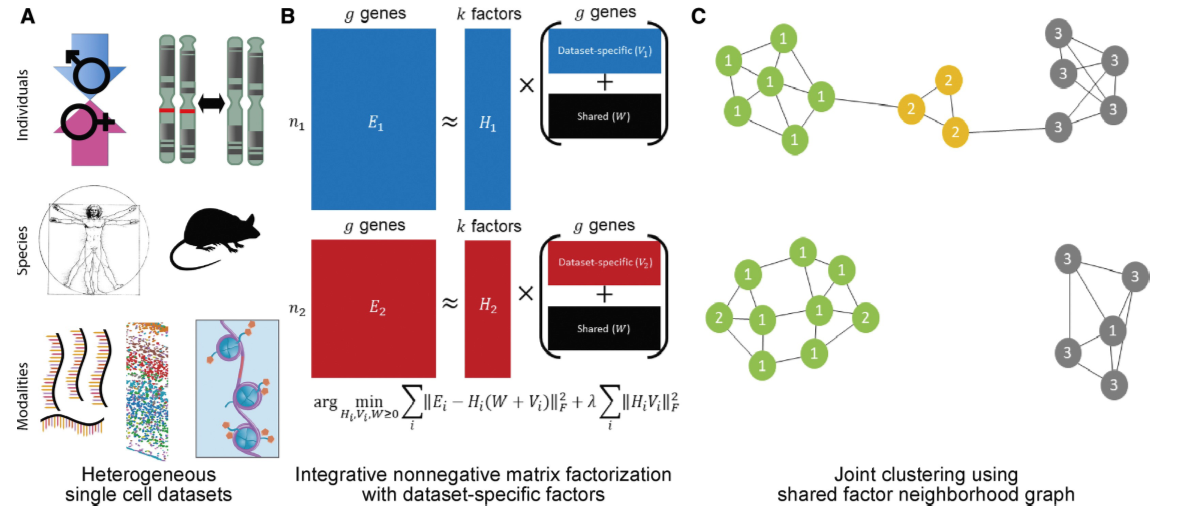
Figure13| Liger整合暗示图。图A:LIGER不错以多种类型数据行动输入;图B:iNMF顺序识别分享和数据集特异的基因;图C:通过iNMF得到的低纬镶嵌空间进行图构建。每一个细胞都依据最大因子负载被分派上一个标签,何况相连到其最隔邻上,然后通过接头比较驾驭因子负载值进行重分析以戒备不实整合
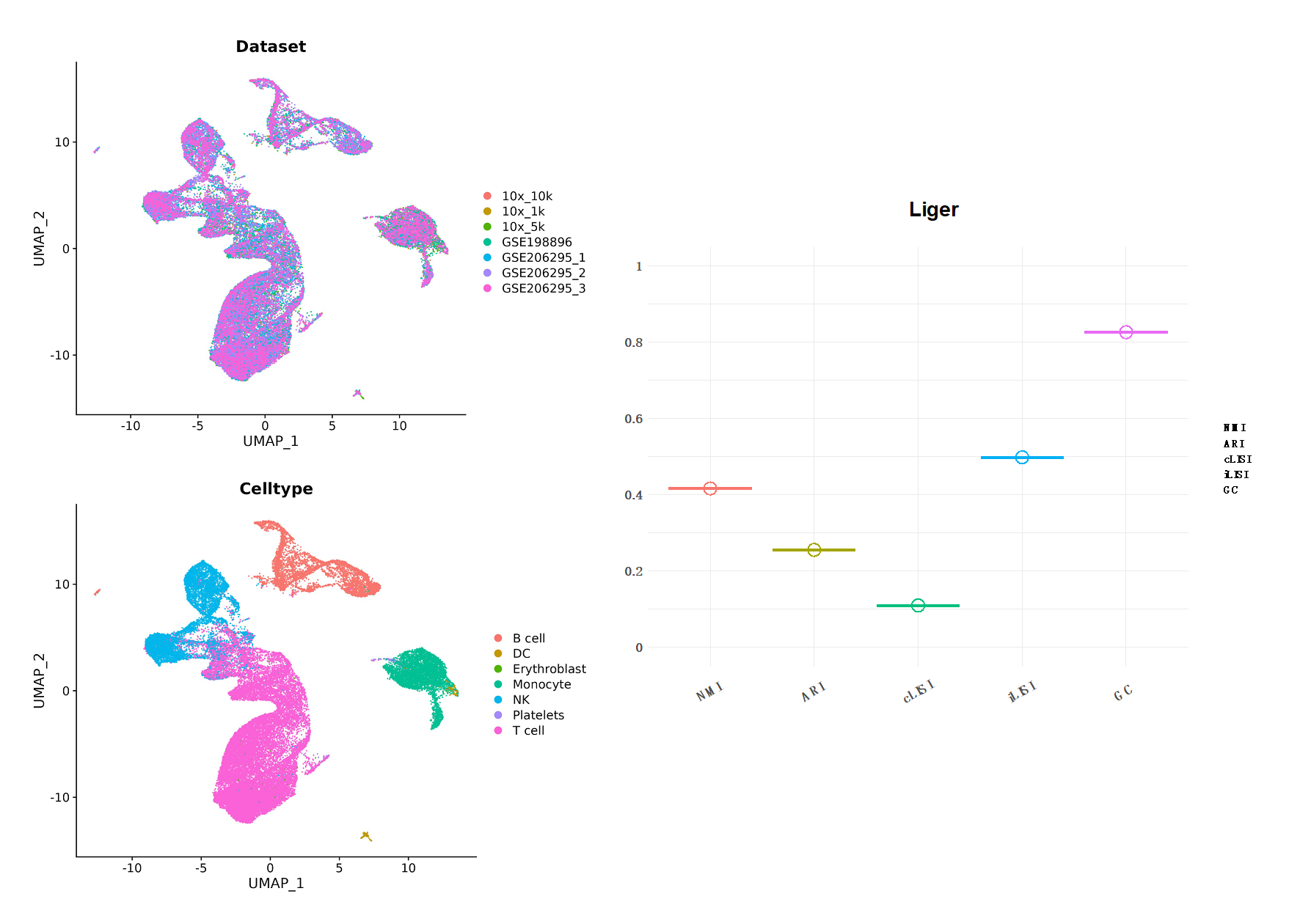
Figure14| LIGER 整合分析成果。左边为UMAP降维图形展示,隔离以数据集和细胞类型分组;右图是成果评分
~ 其他整合顺序请见下回解析 ~ 黄药师
